As máquinas que tudo veem
As máquinas já conseguem enxergar, processando e interpretando a realidade à sua volta. Isso graças a sistemas que simulam a cognição humana e obtêm informações a partir de imagens. A chamada visão computacional é uma das tecnologias a sustentar a engenharia avançada, atuando, sobretudo, no monitoramento e na análise de diversos processos e atividades.
Cientistas de vários países, inclusive o Brasil, investem no aprimoramento dessa tecnologia, visando ampliar seu uso. O objetivo é incorporá-la a sistemas que auxiliem o diagnóstico de doenças, a dispositivos que ajudem pessoas com problemas de fala a se comunicar ou a carros autônomos, entre outras aplicações.
“A visão computacional usa sistemas associados a tecnologias de captura de imagens e suporte de tomada de decisão baseados em algoritmos de análise ou de inteligência artificial”, diz o engenheiro mecânico Paulo Gardel Kurka, da Faculdade de Engenharia Mecânica da Universidade Estadual de Campinas (FEM-Unicamp), importante centro de pesquisa nessa área no país. Estudos envolvendo sistemas de processamento de imagem ganharam relevância nos anos 1970, com o aumento da capacidade de processamento dos computadores e a criação de sensores eletrônicos capazes de capturar imagens e digitalizá-las. Nas décadas seguintes, o avanço de estudos com materiais semicondutores e da miniaturização da eletrônica impulsionou a criação de sistemas mais sofisticados, capazes de obter, processar e analisar com mais eficiência as informações dessas imagens.
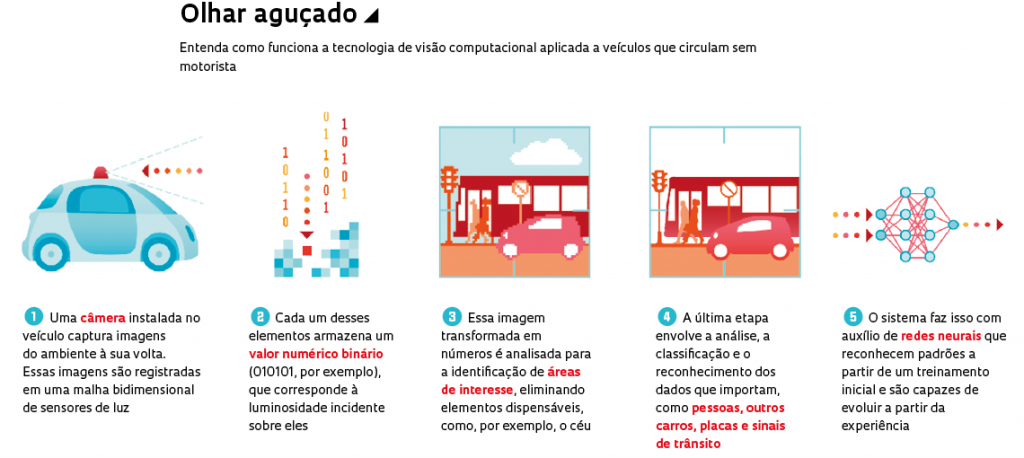
A tecnologia de visão computacional baseia-se em três etapas de processamento de imagem. A primeira envolve a captura da imagem por meio de um dispositivo, como uma câmera. A imagem é registrada em uma malha bidimensional de elementos sensíveis à luz. Cada um desses elementos é capaz de armazenar um valor numérico binário, correspondente à intensidade luminosa que incide sobre ele. Os elementos dessa malha correspondem aos pixels que são usados para a exibição da imagem em uma tela luminosa. “Esses dados são submetidos a técnicas de processamento para melhorar a qualidade da imagem e realçar ou eliminar certas características que não acrescentam informação ao uso que se quer fazer dela”, esclarece Kurka.
Essa segunda etapa é feita por meio de técnicas que identificam e selecionam as regiões da malha de elementos da imagem contendo dados relevantes. “Durante o processamento são definidas as regiões de interesse usadas nas análises posteriores, as quais irão adequar as características de cada imagem aos objetivos que se pretende alcançar.” A última etapa envolve a análise, a classificação e o reconhecimento dos dados de interesse. Isso é feito tendo como base o tipo de aplicação para o qual cada sistema de visão computacional foi desenvolvido.
O mercado global de sistemas de processamento de imagem movimentou US$ 11,9 bilhões em 2018, e pode atingir US$ 17,3 bilhões em 2023, segundo a consultoria norte-americana Markets and Markets. Sete das 20 empresas que mais investem nessa tecnologia estão nos Estados Unidos. A Google é uma delas. A gigante do Vale do Silício foca a aplicação dessa tecnologia em carros autônomos. A ideia é equipá-los com câmeras e sensores capazes de produzir, processar e analisar imagens, diferenciando pessoas de objetos e auxiliando em seu deslocamento. Tudo em tempo real.
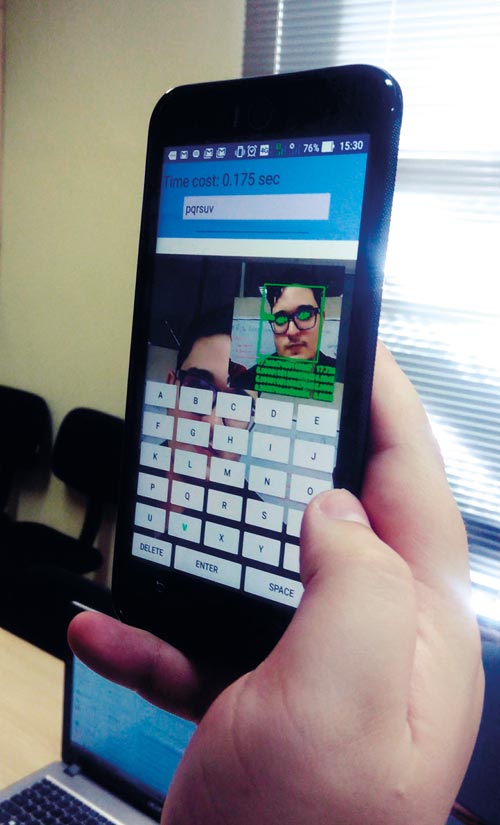
EyeTalk: aplicativo usa a câmera de smartphone para detectar comandos oculares e converter texto em fala.
Os avanços também se dão no setor acadêmico. Dois dos principais centros de pesquisa nessa área no mundo, os institutos de tecnologia da Califórnia (Caltech) e de Massachusetts (MIT), trabalham em sistemas de processamento de imagem com diversas aplicações. Parte do conhecimento gerado no Caltech foi usado na criação de dispositivos de georreferenciamento de robôs enviados à Marte. No MIT, a tecnologia é empregada na identificação de objetos em lugares escuros, no aprimoramento de habilidades humanas em robôs, como sensibilidade e destreza, e em carros autônomos.
No Brasil, uma das aplicações mais frequentes da visão computacional é o monitoramento de processos industriais, um dos pilares da indústria 4.0. É o caso da Autaza, startup de São José dos Campos (SP), que criou um sistema de inspeção industrial em que câmeras fotografam peças em uma linha de produção e usam recursos de inteligência artificial para detectar possíveis defeitos (verPesquisa FAPESP nº 259).
Esses sistemas também são utilizados no país pela indústria madeireira. Pesquisadores da Universidade Estadual Paulista (Unesp), campus de Itapeva, e do Instituto de Ciências Matemáticas e de Computação da Universidade de São Paulo (ICMC-USP), em São Carlos, criaram uma tecnologia capaz de indicar a qualidade das tábuas e a espécie de árvore à qual pertencem (ver Pesquisa FAPESP nº 257). O sistema, em uso pela madeireira Sguario, de Itapeva (SP), verifica se a madeira é de origem legal e a separa por tipo de árvore, o que pode afetar os preços de venda.

Sistemas de processamento de imagem são utilizados por madeireiras para indicar a qualidade das tábuas e a espécie de árvore à qual pertencem.
Comunicação aprimorada
A visão computacional também está sendo usada para auxiliar pessoas com limitações físicas e pacientes hospitalares. A startup paulista Hoobox Robotics, fundada em 2016 por pesquisadores da Unicamp, criou um sistema de reconhecimento facial que capta e traduz expressões em comandos para controlar o movimento de uma cadeira de rodas, sem a necessidade de sensores corporais. A solução, chamada Wheelie 7, pode identificar e reconhecer mais de 10 expressões, como o arquear das sobrancelhas ou o piscar dos olhos. Por meio de uma câmera dirigida ao rosto do usuário, o sistema capta as expressões, interpretadas em seguida por um algoritmo. Um programa transforma-as em comandos, como ir para frente ou girar para a esquerda.
A solução foi desenvolvida com apoio do programa Pesquisa Inovativa em Pequenas Empresas (Pipe), da FAPESP. Por ora, a cadeira de rodas é vendida apenas nos Estados Unidos, por meio de uma assinatura mensal de US$ 300. A Hoobox, em parceria com o Hospital Albert Einstein, de São Paulo, já está testando a tecnologia para detectar comportamentos humanos, como agitação ou espasmos, em pacientes de unidades de terapia intensiva (UTIs).
Na mesma linha, o engenheiro mecânico Marcus Lima, pesquisador da FEM-Unicamp, aplicou a visão computacional na criação de um aplicativo para dispositivos móveis que usa a câmera frontal para detectar comandos oculares, permitindo a comunicação por meio da conversão de texto em fala. O EyeTalk, como foi batizado, é fruto de pesquisas apoiadas pelo Pipe. Segundo Lima, a intenção inicial era criar um sistema para capturar comandos oculares e controlar a movimentação de drones. “Durante o projeto, vi que poderia adaptar a tecnologia para que pudesse ser utilizada por pessoas com comprometimento da fala”, relembra.

Dispositivo criado pela Hoobox capta expressões faciais.
A solução funciona como um teclado virtual, com teclas que piscam em sequência. A ideia é simples: um tablet ou smartphone contendo o aplicativo é acoplado a um suporte diante da pessoa. A câmera frontal fica direcionada para os olhos do indivíduo, que, com um piscar, seleciona as letras de interesse, formando palavras e frases. Essas frases, em seguida, são convertidas em áudio por uma voz digital. A solução é semelhante à usada pelo físico britânico Stephen Hawking (1942-2018), que sofria de esclerose lateral amiotrófica (ELA) e passou a maior parte da vida imobilizado em uma cadeira de rodas sem conseguir falar. “O problema”, diz Lima, “é que os modelos disponíveis podem custar até £ 15 mil [cerca de R$ 75 mil], inacessíveis para a maioria das pessoas”.
Lima está hoje à frente da Acta Visio, empresa criada em 2017 para desenvolver soluções baseadas em visão computacional. O pesquisador e sua equipe trabalham no protótipo de um sistema de processamento de imagem para monitorar a higienização das mãos de profissionais da saúde. O objetivo é reduzir infecções hospitalares e fornecer dados quantitativos que possam auxiliar o gestor do hospital na avaliação dos procedimentos de higienização. Os primeiros testes serão realizados em abril no Hospital Universitário Cajuru, em Curitiba, em parceria com a empresa de gestão hospitalar 2iM.

…e as traduz em comandos para controlar uma cadeira de rodas.
Diagnóstico mais preciso
Ainda na área da saúde, sistemas de processamento de imagem são usados na identificação de biomarcadores que auxiliam o diagnóstico, o prognóstico e o tratamento de alguns tipos de câncer, como os de mama. Muitos desses tumores são descobertos quando a doença está em estágio avançado. A detecção precoce passa pelo exame clínico e pela mamografia, feita com aparelho de raio X capaz de identificar lesões iniciais com potencial cancerígeno. Em muitos casos, para chegar a um diagnóstico mais preciso, recorre-se à biópsia, a retirada de um fragmento de tecido suspeito para análise. Em média, de cada oito biópsias realizadas apenas uma é positiva.
Uma inovação criada pelo professor de informática biomédica e física médica Paulo Mazzoncini de Azevedo Marques, da Faculdade de Medicina de Ribeirão Preto da USP, permite identificar padrões associados a esse tipo de tumor, podendo reduzir o número de biópsias. “Usamos a visão computacional para criar um algoritmo capaz de detectar e analisar microcalcificações, pequenos cristais de cálcio existentes na mama e representados como pequenos pontos claros na imagem, indicando se estão associados a uma lesão benigna ou maligna [câncer]”, diz. “O algoritmo avalia cada pixel da imagem dentro de vizinhanças específicas e, a partir da extração de atributos quantitativos, identifica variações que podem estar associadas a um padrão suspeito.”
No setor da saúde, a visão computacional pode auxiliar o diagnóstico de câncer e doenças autoimunes
O modelo também pode ser treinado para o reconhecimento de padrões que apoiem o diagnóstico e o tratamento em casos de tumores de pulmão e doenças reumáticas autoimunes. Com base na variação de tons de cinza em imagens de lesões suspeitas captadas por aparelhos de raio X, ressonância magnética e tomografia computadorizada, e valendo-se de algoritmos de inteligência artificial, é possível analisar de modo isolado as regiões suspeitas, comparando suas características com as de lesões identificadas em imagens de outros pacientes anteriormente diagnosticados.
“Nossa intenção é que o sistema utilize esses dados acumulados e aprenda pela experiência, sendo capaz de estabelecer padrões que auxiliem o médico a reconhecer onde estão os achados significativos nas imagens, suas características e se eles estão associados a tumores mais agressivos”, esclarece o pesquisador. A solução está sendo aprimorada a partir de informações disponíveis em bases de dados clínicos locais e públicas. A ideia é treinar o sistema e refinar sua capacidade de reconhecimento de padrões associados a essas doenças.
Fonte: Pesquisa FAPESP